Leveraging Image-based Prior in Cross-Season Place Recognition
Abstract-In this paper, we address the challenging problem of single-view cross-season place recognition. A new approach is proposed for compact discriminative scene descriptor that helps in coping with changes in appearance in the environment.We focus on a simple effective strategy that uses objects whose appearance remain the same across seasons as valid landmarks.Unlike popular bag-of-words (BoW) scene descriptors that rely on a library of vector quantized visual features, our descriptor is based on a library of raw image data (e.g., visual experience shared by colleague robots, publicly available photo collections from Google StreetView), and directly mines it to identify landmarks (i.e., image patches) that effectively explain an input query/database image. The discovered landmarks are then compactly described by their pose and shape (i.e., library image ID, and bounding boxes) and used as a compact discriminative scene descriptor for the input image. We collected a dataset of single-view images across seasons with annotated ground truth, and evaluated the effectiveness of our scene description framework by comparing its performance to that of previous BoW approaches, and by applying an advanced Naive Bayes Nearest neighbor (NBNN) image-to-class distance measure.
Members: Taisho Tsukamoto,
Kanji Tanaka
Relevant Publication:
Leveraging Image-Based Prior in Cross-Season Place Recognition
Robotics and Automation (ICRA), 2015 IEEE International Conference on
Ando Masatoshi, Chokushi Yuuto,
Tanaka Kanji, Yanagihara Kentaro
Bibtex source, Document PDF
Acknowledgements: This work is supported in part by JSPS KAKENHI
Grant-in-Aid for Young Scientists (B) 23700229, and for Scientific Research (C)
26330297.
Members Chokushi Yuuto Tanaka Kanji Yanagihara Kentaro
Cross season university
campus dataset
The cross season dataset consists of 19,263 images
taken around a university campus, using a hand-held camera as a monocular
vision sensor. The images have been manually annotated to generate ground
truth. The datasets have been collected across four seasons over a year and
cover all the four seasons, and each of query, database, and library images
(i.e., consists of 3 x 3 x image collections).
DOWNLOAD: cross_season_university_campus.zip
Description of files:
cross_season/
SP/
query/
db/
library/
gt/
SU/
query/
db/
library/
gt/
AU/
query/
db/
library/
gt/
WI/
query/
db/
library/
gt/
Directory containing images four different seasons (SP/, SU/, AU/, WI/) and
ground truth files (gt/). The ground truth files have
the following layout:
Every line consists of [QID] [AID] [BID] [EID]
QID and AID are the image ids of a query image and the corresponding ground
truth database image. BID and EID define the area [BID,EID] of the image ids of
relevant database images that can be used as positive training data for the
query image (not used in the current paper).

Fig. 1. Single-view cross-season place recognition. The appearance of a place may vary depending on geometric (e.g., viewpoint trajectories and object configuration) and photometric conditions (e.g., illumination).Such changes in appearance lead to difficulties in scene matching, and thereby increasing the requirement for a highly discriminative, compact scene descriptor. In this figure, the panels (top-left, top-right, bottom-left,bottom-right) shows visual images acquired in autumn (AU:2013/10), winter(WI:2013/12), spring (SP:2014/4), and summer (SU:2014/7), respectively.
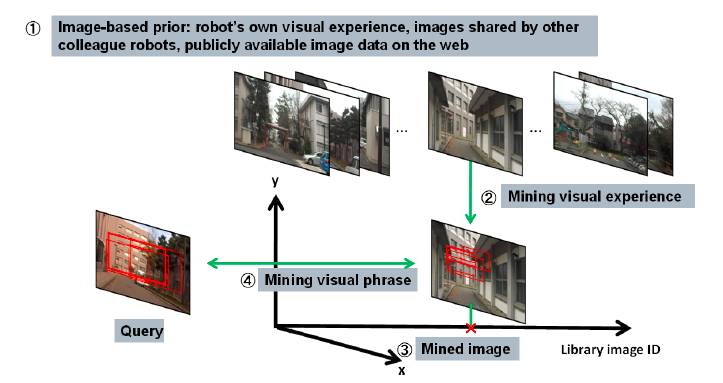
mining visual phrases for landmark discovery

landmark comparison for scene matching
Fig. 2. System overview: proposing, verifying and retrieving landmarks for cross-season place recognition. The proposed framework consists of three distinct steps: (1) landmarks are proposed by patch-level saliency evaluation(red boxes in “Query”), (2) landmarks are verified by mining the image prior to find similar patterns (red boxes in “Mined image”), and (3) landmarks are retrieved by using the bag-of-bounding-boxes scene descriptors (colored boxes in the bottom figure).
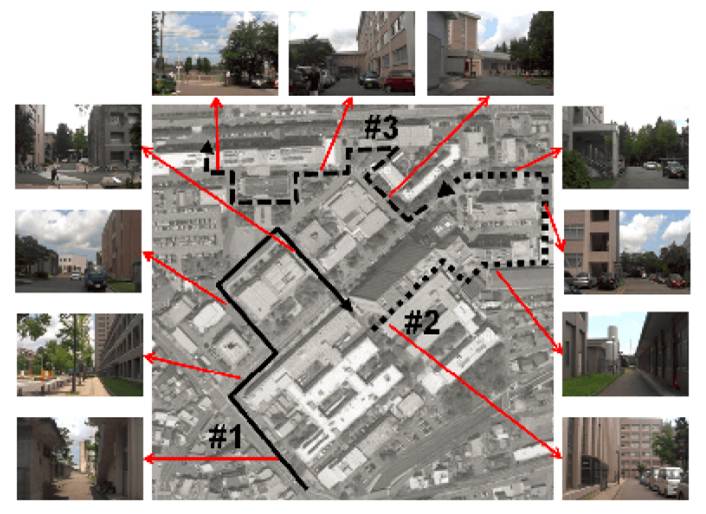
Fig. 3. Experimental environments and viewpoint paths.

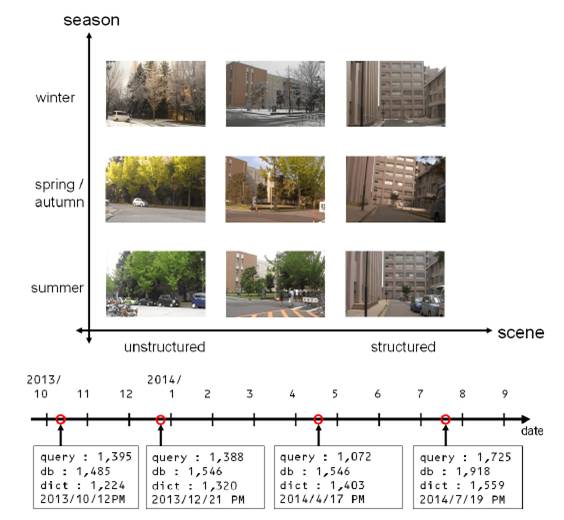
Fig. 4. Datasets. Image datasets are collected for various types of scenes and
across seasons (top). The dataset consists of three datasets of query,database,
and library images collected during four different seasons over a year
(bottom).

Fig. 5. Examples of scene retrievals. From left to right, each panel shows a
query image, the ground truth image, the database image top-ranked by the BoW
method and by the proposed method.


Fig. 6. Examples of proposing, verifying and retrieving landmarks. From left to
right, input image, saliency image, landmark proposal (blue bounding box),
mined library image, landmark discovered w.r.t. the library image’s coordinate, and the top-ranked database image.
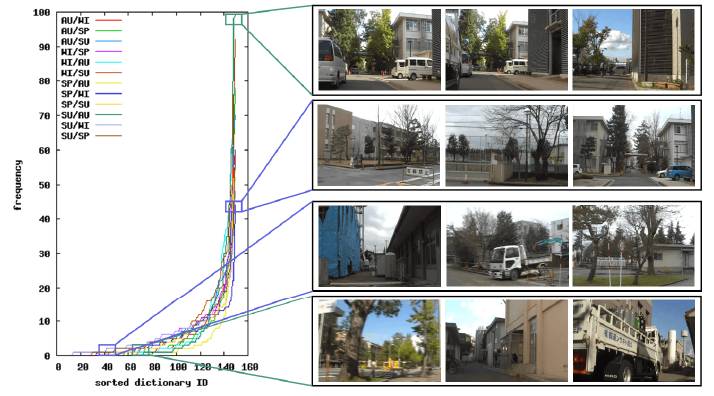
Fig. 7. Frequency of library images.
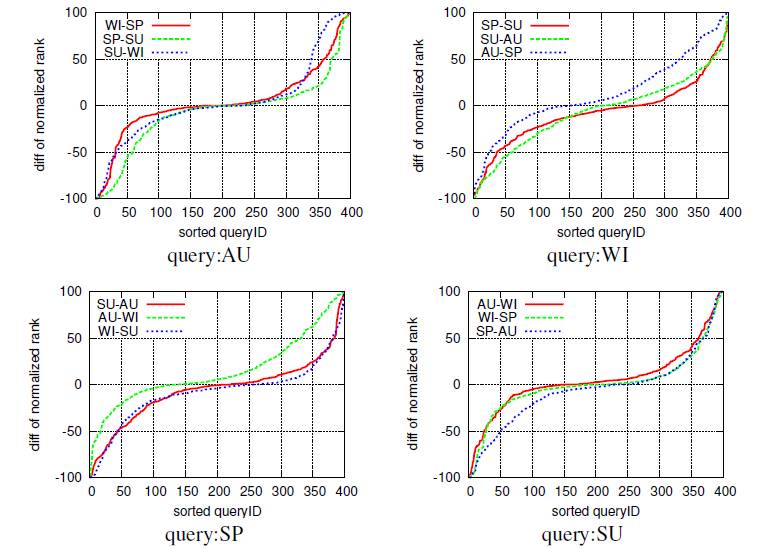
Fig. 8. Comparison across seasons. Horizontal axis: sorted query ID.Vertical axis: difference of normalized ranks Δr=rS1?rS2 between different season databases. S1 and S2 are two different seasons indicated in the key(e.g., “WI-SP” indicates Δr = rWI ?rSP).
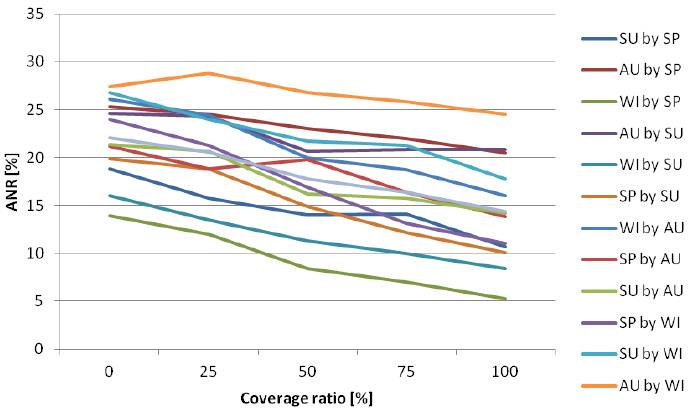
Fig. 9. Results for NBNN image-to-class distance measure.