Bag-of-Bounding-Boxes
Abstract-Object-level view image retrieval for robot vision applications has been actively studied recently, as they can provide semantic and compact method for efficient scene matching. In existing frameworks, landmark objects are extracted from an input view image by a pool of pretrained object detectors, and used as an image representation. To improve the compactness and autonomy of object-level view image retrieval, we here present a novel method called “common landmark discovery”. Under this method, landmark objects are mined through common pattern discovery (CPD) between an input image and known reference images. This approach has three distinct advantages. First, the CPD-based object detection is unsupervised, and does not require pretrained object detector. Second, the method attempts to find fewer and larger object patterns, which leads to a compact and semantically robust view image descriptor. Third, the scene matching problem is efficiently solved as a lower-dimensional problem of computing region overlaps between landmark objects, using a compact image representation in a form of bag-of-bounding-boxes (BoBB).
Members
Tanaka Kanji, Ando Masatoshi, Inagaki Yosuke, Chokushi
Yuto, Hanada Shogo
Relevant Publications:
Common Landmark Discovery for Object-Level View Image Retrieval
Proc. IAPR Asian Conference on Pattern Recognition 2013,
Ando Masatoshi, Tanaka Kanji, Inagaki Yousuke, Chokushi Yuuto, Hanada Shogo
Bibtex source, Document
PDF
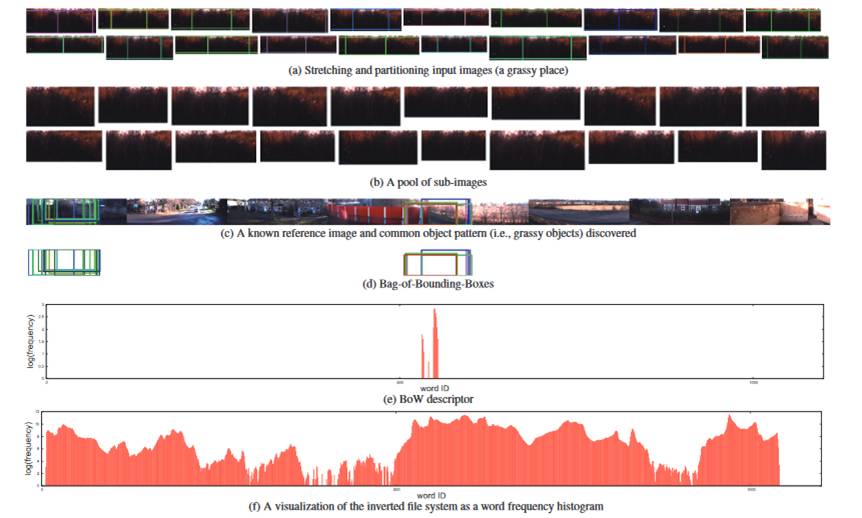
Fig. 1. The bag-of-bounding-boxes (BoBB) image representation. (a) The algorithm pipeline: ?rst, a small number of subimages are sampled from thequery and database images; second, each subimage is characterized by common landmark objects discovered between the input and the dictionary images;third, each of the common landmark objects is represented in the compact form of a bounding box. (b) Common landmark discovery: a reference image is randomly partitioned into non-overlapping rectangular patches, and each patch is viewed as a visual phrase, in which a group of co-located SIFT features can be bundled together; a voting map is then constructed by computing the average similarity at the level of visual phrase between the input and reference images; ?nally, object localization becomes a task of segmenting out the dominant region in the form of a bounding box.

Fig. 2. Dictionary images.

Fig. 3. View images used for experiments.

Fig. 4. Results of common landmark discovery. From left to right: the input subimage, the dictionary image with bounding box overlaid, the voting map, and the bounding box. From top to bottom: pole, tree, and building with similar appearances are automatically discovered as common landmark objects.